从“Prompt”到“Context”:大模型应用的关键

从 chatgpt 发布开始,“Prompt Engineering”(提示词工程)一直是AI领域的热门话题,很多人喜欢把他读成 Promote,很有意思。随着大模型和智能体(Agent)的普及,越来越多的开发者、产品经理和研究者发现:决定AI输出质量的,早已不是一句巧妙的提示语,而是你能否为模型“工程化”地提供丰富、精准、结构化的上下文。最近,大神 Andrej Karpathy 更是把 “Context Engineering”(上下文工程)成为新一代AI实践者的共识与热词。
什么是“Context Engineering”?
传统的Prompt Engineering,关注于如何写出一句能激发模型最佳表现的指令。Context Engineering 则是更高维的系统思考:如何为AI模型动态、系统地准备好一切“它需要的信息和工具”,让它有能力解决复杂任务。
根据philschmid.de的原文 ↗,上下文不仅仅是用户输入的那句话,而是包括:
- 系统指令(System Prompt):定义模型角色和行为的规则、范例。
- 用户提示(User Prompt):当前要解决的具体问题。
- 状态/历史(短期记忆):对话历史、上下文状态。
- 长期记忆:跨会话的知识、用户偏好、项目总结等。
- 外部检索信息(RAG):从文档、数据库、API实时检索的内容。
- 可用工具:模型可调用的函数、API、插件等。
- 结构化输出定义:如JSON、YAML等格式要求。
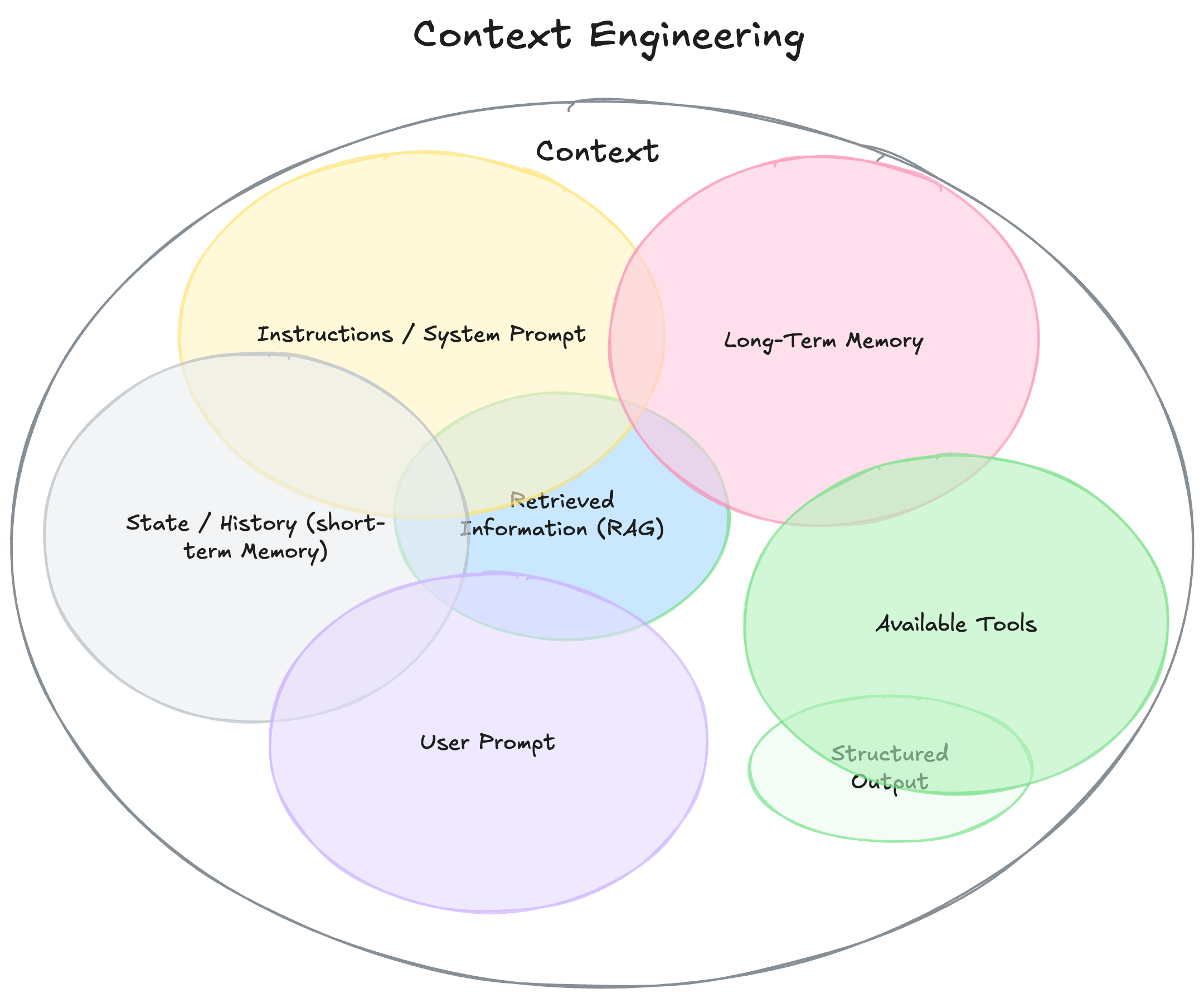
Context Engineering 的本质,是为AI“搭建舞台”,让它在有限的“工作记忆”里,最大化地获得解决问题所需的知识与能力。
为什么“上下文工程”才是决定大模型体验的关键?
Hacker News 上的一条高赞评论说得很直白:现在Agent(智能体)失败的主要原因,已经不是模型不够强,而是上下文给得不对、不全、不优。换句话说,AI的“魔法感”不在于代码写得多巧妙,而在于你能否把所有相关信息、历史、外部知识和工具有机地组合起来,放进模型的“脑子”里。
举个例子:一个“廉价Demo级”AI日程助手,只能根据用户的“明天有空吗”机械回复“明天可以,请问几点”。而一个“魔法感”十足的Agent,会自动查你的日历,回溯你和对方的邮件风格,识别对方身份,调用发送邀请的接口,最终发出:“Jim,明天我排满了,周四上午有空,已发邀请,看看合适不?”
这种差距,并非靠更大的模型、更复杂的算法解决,而是靠上下文工程的系统设计。
思辨与实践经验
结合Hacker News的讨论,社区对Context Engineering有不少深刻洞察和实用建议:
- 短上下文优先原则:多数大模型最能理解前1k-10k tokens,超长上下文窗口准确率会迅速下降。关键信息必须放在最前面,冗余信息要压缩或摘要。
- 多Agent分工协作:复杂任务不要让一个Agent带太多工具/上下文,应拆分为多个小Agent,彼此规划与交接。
- 格式与结构重要:把数据、规则、指令、历史用结构化格式(如JSON、YAML)表达,远比纯文本更易于模型准确理解。
- 科学评估而非“炼丹”:有效的上下文工程需要持续的自动化评测(evals),用实验数据迭代优化,而不是靠“玄学”试错。
- “Prompt”与“Context”并非纯语义之争:社区有观点认为两者本质一样,都是“给模型输入一坨东西”,但在实际工程中,动态生成、组合、裁剪上下文远比单一提示复杂得多。
推荐读一下Drew Breunig的Context Engineering系列博客 ↗:详细讲解上下文腐化、剪枝、工具装载等技巧。
总结
大模型应用系统的能力边界,越来越取决于你能否“工程化”地管理和组织上下文。Context Engineering不是一句新口号,而是AI产品和Agent落地的核心竞争力。它要求跨学科的系统设计、数据治理、工具集成与自动化评测能力。
Agentic AI时代,拼的不再是“会写prompt”,而是谁能为AI“搭好舞台”,让它在正确的时间、用正确的方式、拿到正确的信息和工具,完成真正复杂的任务。
Member discussion